Continue with my previous blog Customised Quick Start of Confluence Data Center on AWS. Now I have both my on-premise Confluence and AWS Confluence up and running. The next step is to migrate all existing data into AWS.
Due to the large size of data, the migration should be an on-going process till the final DNS cutover. Here is what I did, and worked well.

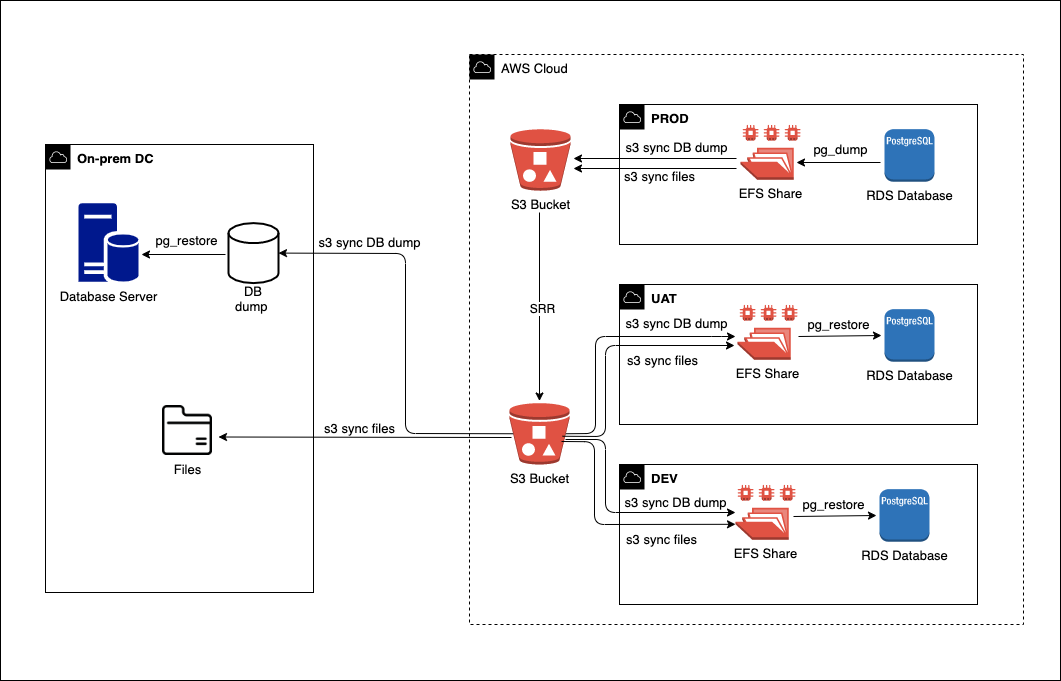
You can use datasync, cloudendure or even snowball to migrate the data into AWS, but in my opinion S3 sync is the best in term of design simplicity and maintenance effort. Take AWS datasync for example, it claims 10 times faster than open source sync tool. But it requires a dedicated virtual machine which runs as the datasync agent, also it does not support migrating the data that is on local disk, it has to be on a shared file system.
In my case, using S3 sync took a bout 17 hours to migrate 1TB data into S3 at the first run. The following runs only sync the changed or new files, and it normally can finish within 1 hour out of which about 30-40 minutes were spent on comparing the files to decide which ones should be synced due to the large amount of files. Within this solution, we just need to run a daily sync to get all the delta in S3 till the final cut over day.
After the cutover is done, we sync the files back to the on-premise datacenter from S3. So we can have a copy of data on-premise which is used for the disaster recovery site. Also we use the solution for refreshing the lower environment.

One thought on “Migrate Confluence Data to AWS”