I have been recently working on improving our performance monitoring against Jira and Confluence. And here I want to share a few things that I learned, and hope they are useful to you as well.
In high level, we have done:
- Setup both black box monitoring (CPU, memory, IO, Error log …) and white box monitoring (Availability, Response time…).
- Keep track of the history data, so we can measure and make prediction.
- Automate monitoring and troubleshooting process as possible as we can.
In details, we have implemented:
- Use Splunk to do black box monitoring via MNON.
- Use Spunk to collect all sorts of log (reverse proxy, jira/confluence, database) to do white box monitoring via dashboard or alerts.
- Send Splunk alerts to Slack if the pre-defined conditions has been triggered.
- Let the Bot do some initial troubleshooting when the alerts are received.
Here are some examples:
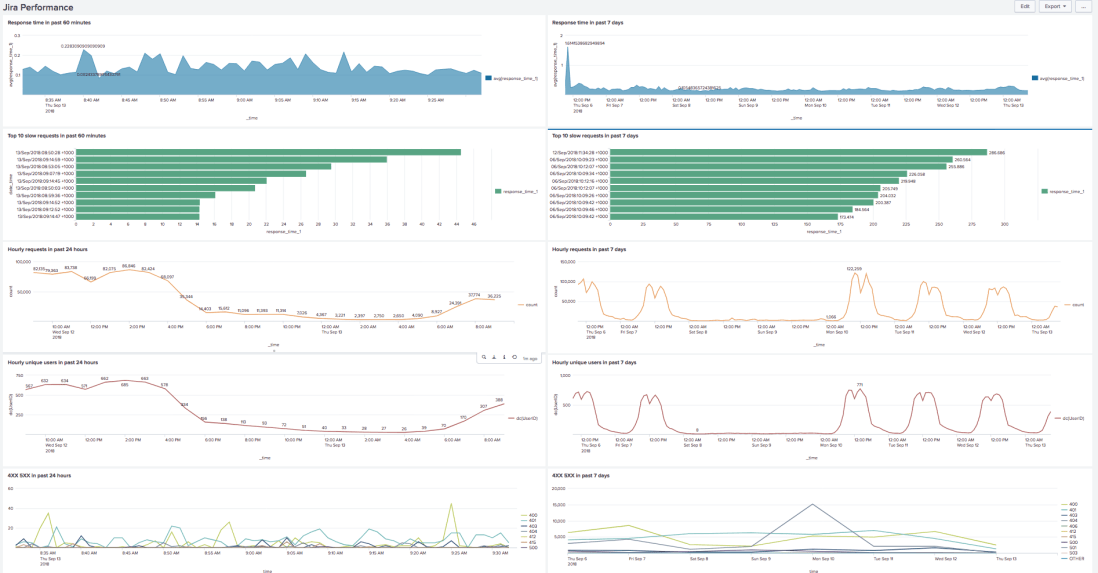
Jira performance dashboard which shows the average response time, top 10 slow requests, hourly users and request numbers, http error codes etc.
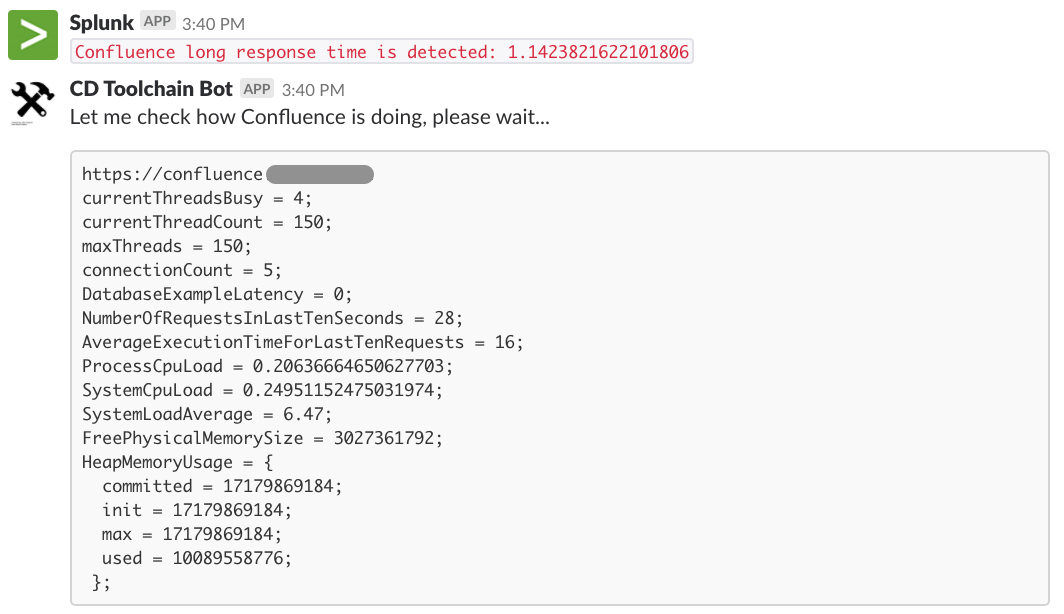
When Jira/ Confluence long response is detected, our Bot checks the status of Jira/ Confluence straight way. So we can tell whether it is a long lasting or one off issue by looking at the key metrics.

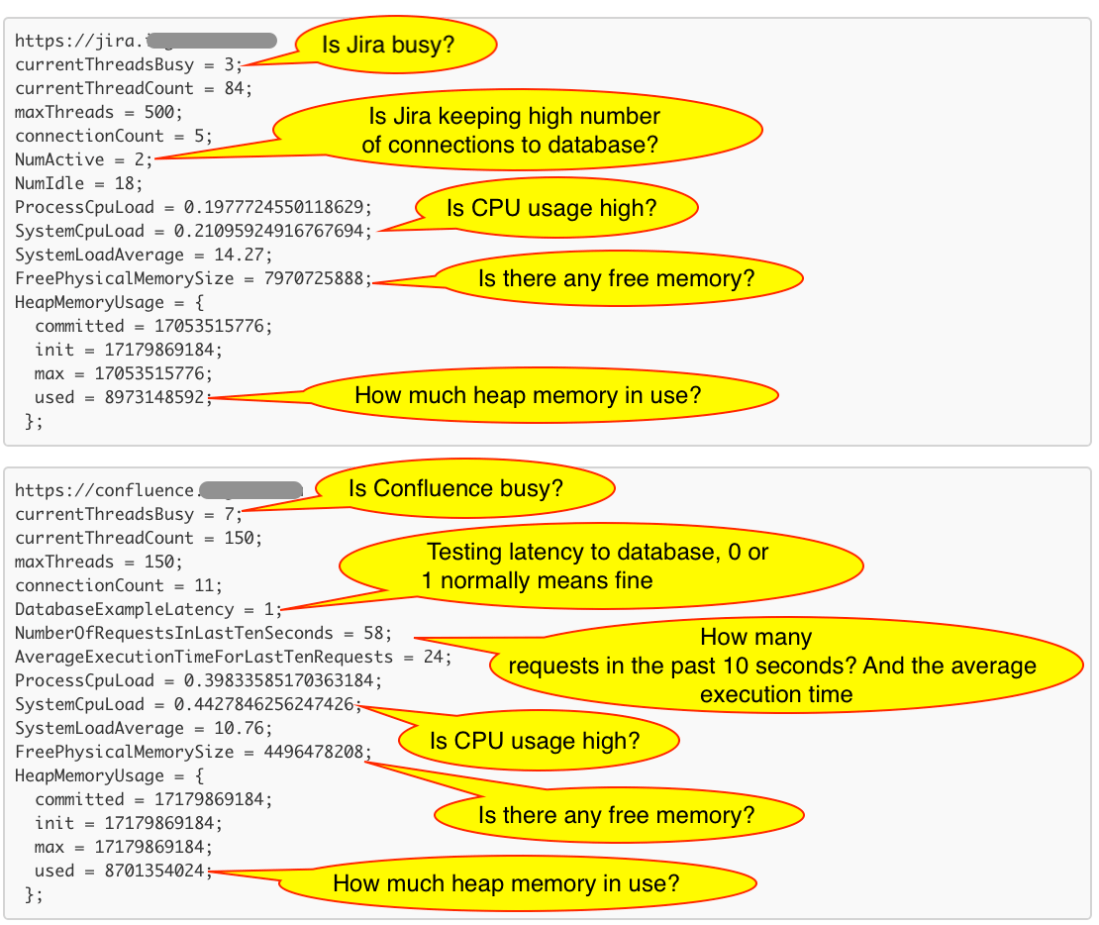
What does those key metric mean? Here you go.
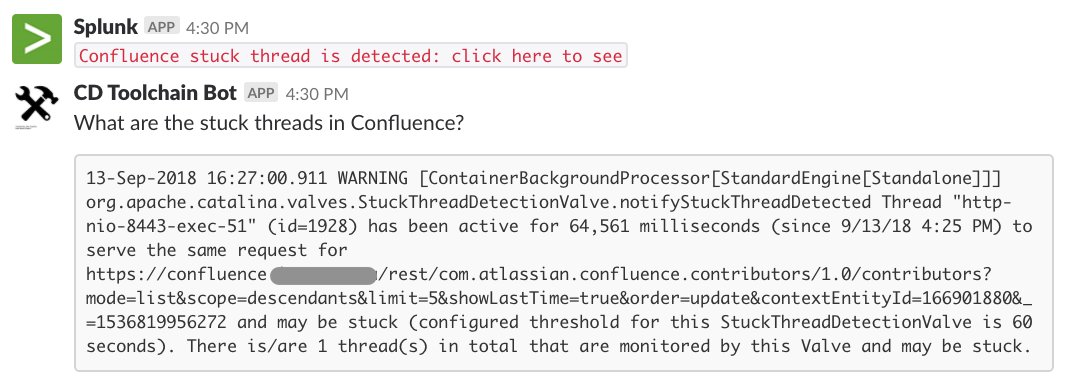
When Confluence stuck thread (or slow request) is detected, our Bot checks what that thread is about. In the following example, it shows the Contributor macro takes a long time to complete. That is how we found out this known performance issue which exists in Confluence version prior 6.12.

One thought on “Jira and Confluence Performance Monitoring Part One”