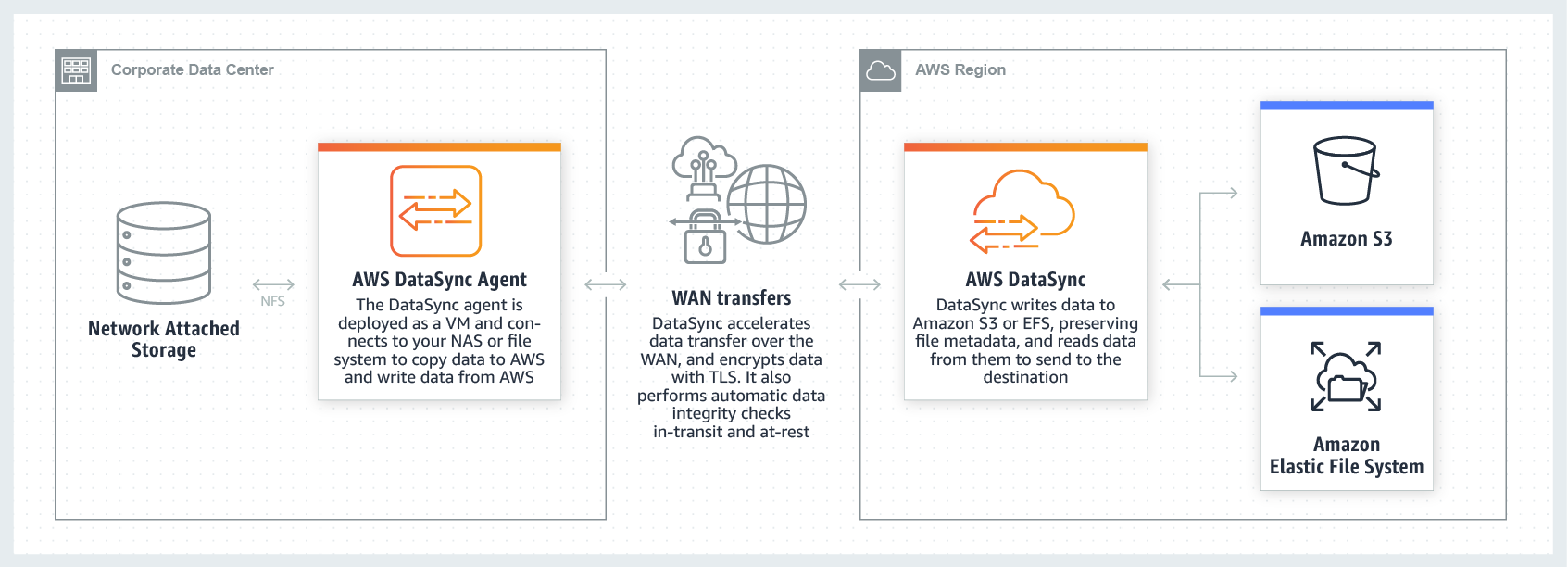
I am currently working on a data migration project (from on-premise to AWS cloud). Also I would like to use the method to sync the data from AWS back to on-premise for DR purpose after we have done the migration.
The total data size is about 1TB, and it is an online application data which is read and modified by users frequently. Regarding the data size and the change frequency, offline migration is not applicable here. So Snowball or Snowball Edge is out of my consideration.
I am looking at AWS DataSync and the plain S3 Sync. BTW, just as a FYI if the data source and destination are from the same region, S3 normally performs better than S3 Accelerator due to less hops. Check it out by yourself if you are interested.
AWS DataSync looks like a good candidate as the migration tool. But it requires extra setup and maintenance, also it comes with some limit e.g it only supports shared storage (NFS or SMB). AWS S3 sync command is handy, as it is part of the AWS CLI, no extra setup is required.
| Migration Tool | Requirements | Performance | Cost | Maintenance |
| DataSync | – Agent VM – Firewall change – NFS or SMB | – Optimised data transfer protocol, it claims 10 times faster than open source tool. – Scalable with multiple agents | – A bit extra cost: AWS DataSync fee for data copied $0.0125 per gigabyte (GB) in Sydney region | – Requires VM maintenance if it is not a once-off migration |
| S3 Sync command | – AWS CLI | – May be slow when migrating large files | – No extra cost: All data transfer in $0.00 per GB | – No maintenance is required |
So if there is no big gap in the tooling performance, I think I will still go with S3 Sync. As I have setup DataSync yet, so I don’t know answer. I will keep this post updated once I get the test results, so you can use it as reference. Just please bear in mind that besides the tooling itself, there are a few things can impact the performances as well. e.g the disk speed, memory size, CPU speed and network etc.

Just checking if you did that test in the end to compare speeds?
Wish I read this earlier, DataSync just charged us a massive bill for doing the same thing as S3 Sync. S3 Sync is the way to go