We are implementing monorepo internally to let all teams work closely. As there are dependencies between each team's work, it is important to understand and track the cross-project changes that go into the monorepo. Monorepo is a good practice that brings in better collaboration, but it also introduces some inconveniences. The biggest complaints I heard … Continue reading git sparse-checkout command for monorepo
Ansible example – get dictionary value
Here is a quick sample to show how Ansible can get the value from a dictionary: https://gist.github.com/jc1518/b249a6930a1dc7bfcf85181df02844dd To test it: ansible-playbook accounts.yaml -e env=dev
New EFS access control is available now
I have been using EFS for a while to store my shared application data. Generally speaking it is good in terms of scalability and performance. My concern is mostly around the security, as it only uses security group to control the access. It is a risk if it is used in a multi-tenants environments, as … Continue reading New EFS access control is available now
AWS DataSync vs S3 Sync
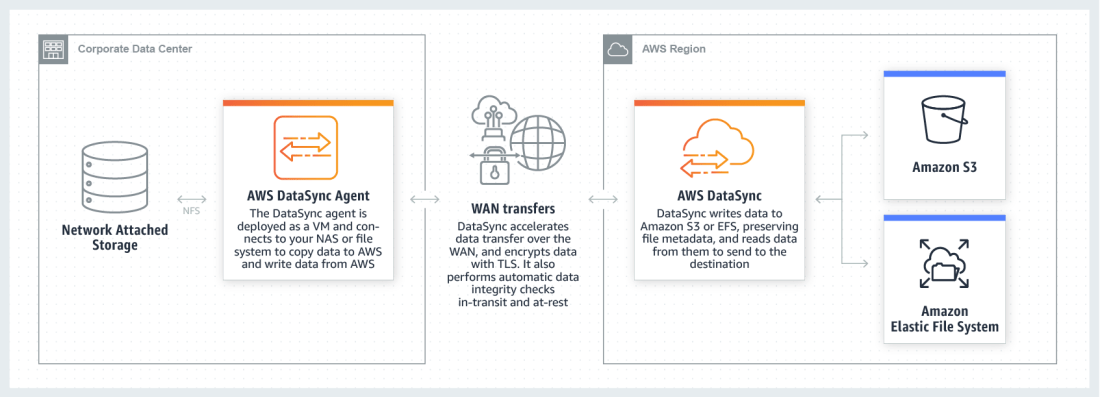
I am currently working on a data migration project (from on-premise to AWS cloud). Also I would like to use the method to sync the data from AWS back to on-premise for DR purpose after we have done the migration. The total data size is about 1TB, and it is an online application data which … Continue reading AWS DataSync vs S3 Sync
How Confluence Data Center Manage the Index File?
When building Confluence Data Center on AWS, I was wondering how Confluence Data Centre manages the index file. As we run Confluence cluster in auto-scaling group, the Confluence nodes come and go (not that frequent though, as Confluence is not good at dynamic scaling. It is more schedule based scaling). The newly launched instance gets … Continue reading How Confluence Data Center Manage the Index File?
