We recently migrated Confluence Data Center to AWS. And by using the Read-Only mode, we achieved zero downtime! Everything works well since the migration.
During the working hours, the normal load is between 6000 to 7500 RPM (request per minute). And the two node cluster is still able to provide satisfying response time while the load ramps up to 8000+ RPM.
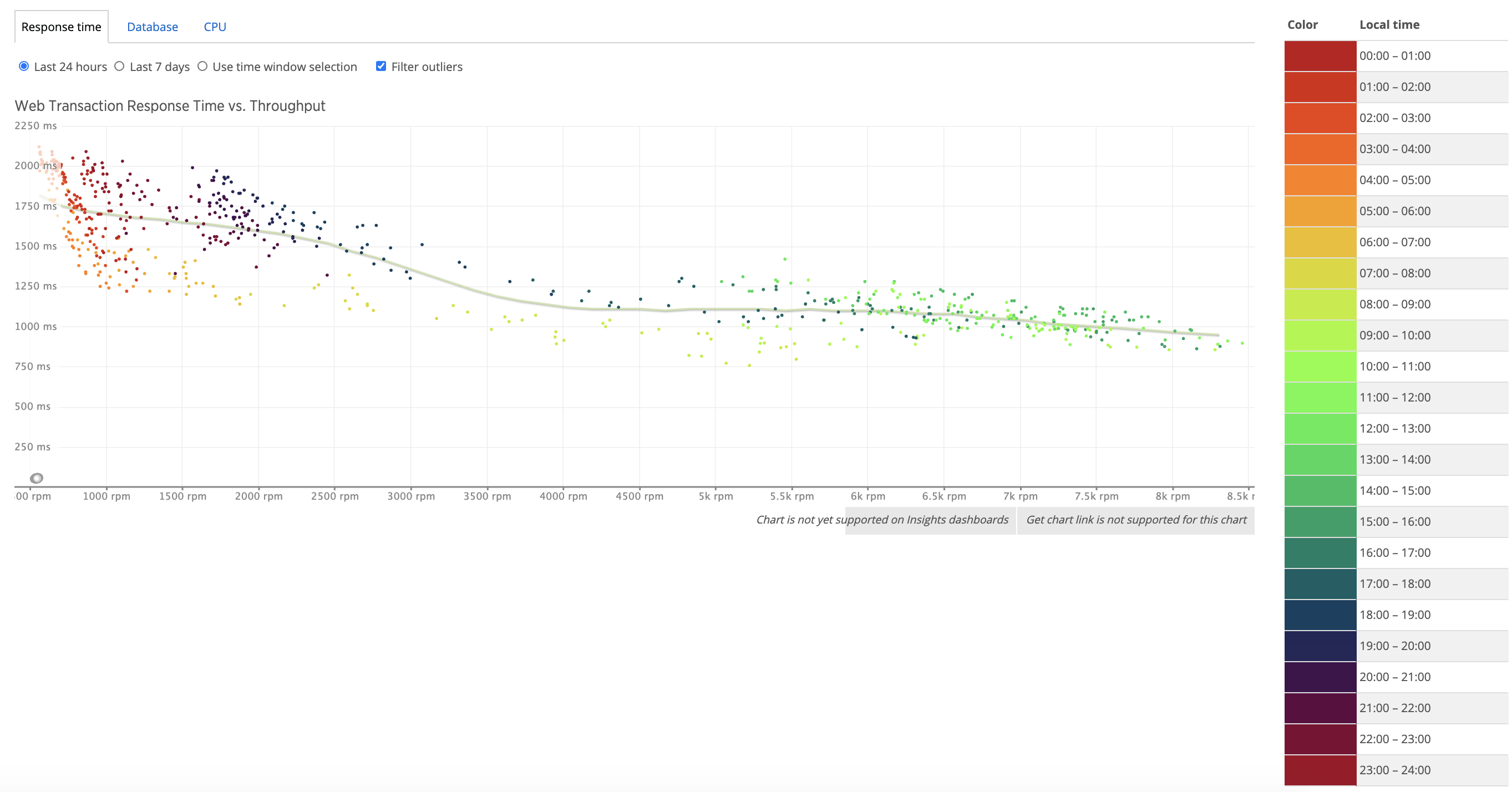
But I did notice something that I was not aware before. In AWS, we use application load balancer to divert the traffics to the target group which is associated with the Confluence auto-scaling group. And I found out that load is not well balanced across the two backend EC2 instance no matter the load balancing algorithm is Round Robin or Least Open Connection. The ratio is always between 7:3 to 8:2.

I think the cause is that Confluence needs to use Sticky Session (we set Stickiness duration = 1 day). This means that a user’s first request is routed to a backend instance using the load balancing algorithm. But the subsequent requests are then forwarded to the same instance util the sticky session expires.
According to 12 Factors, sticky session should never be relied on. A better solution is to keep the session information into a caching store (e.g Redis). In that way, all instances will be treated equally. And the session won’t need to be rebuilt while running a rolling update of instance (e.g Patching OS). May be this is something Atlassian can improve.
Sticky sessions are a violation of twelve-factor and should never be used or relied upon. Session state data is a good candidate for a datastore that offers time-expiration, such as Memcached or Redis.
So the take way is that regardless the load balancing algorithm the loads are not always balanced across the backend instances if sticky session is in use. Therefore you need to choose the right instance size to handle the load spikes. Ideally, it should be able to handle 100% of the load if considering of losing one node/ AZ.
