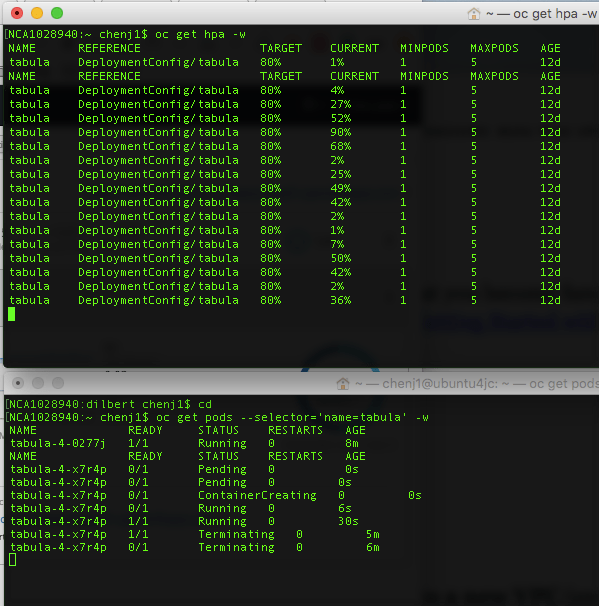
I did a quick test of the HPA (Horizontal Pod Autoscaling) on OpenShift, here are some key findings:
- Heapster metric is not near realtime, it is about 2 minutes delay in my test.
- HPA only has one threshold to decide when to scale up or scale down. I think it makes sense, as pods normally take a few seconds to spin up. Really no point to have two thresholds.
- HPA follows the common autoscaling practice – quick scale-up, slow scale-down.
Load test: 30 concurrent sessions/ 8000 requests/ 62.710 seconds duration.
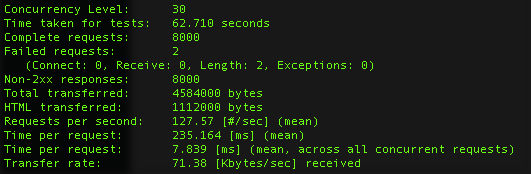
What I observed: HPA spins up a new pod when the CPU usage is over 80%. It is about 2 minutes delay. As when the scaling happens, the test has already completed for more than 1 minute. HPA took longer time to scale down. In my test, the pod has been running for about 5 minutes before gets terminated.
scale up
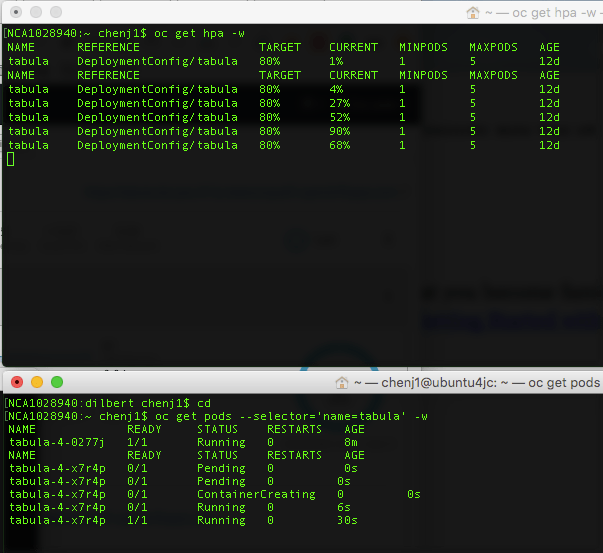
scale down