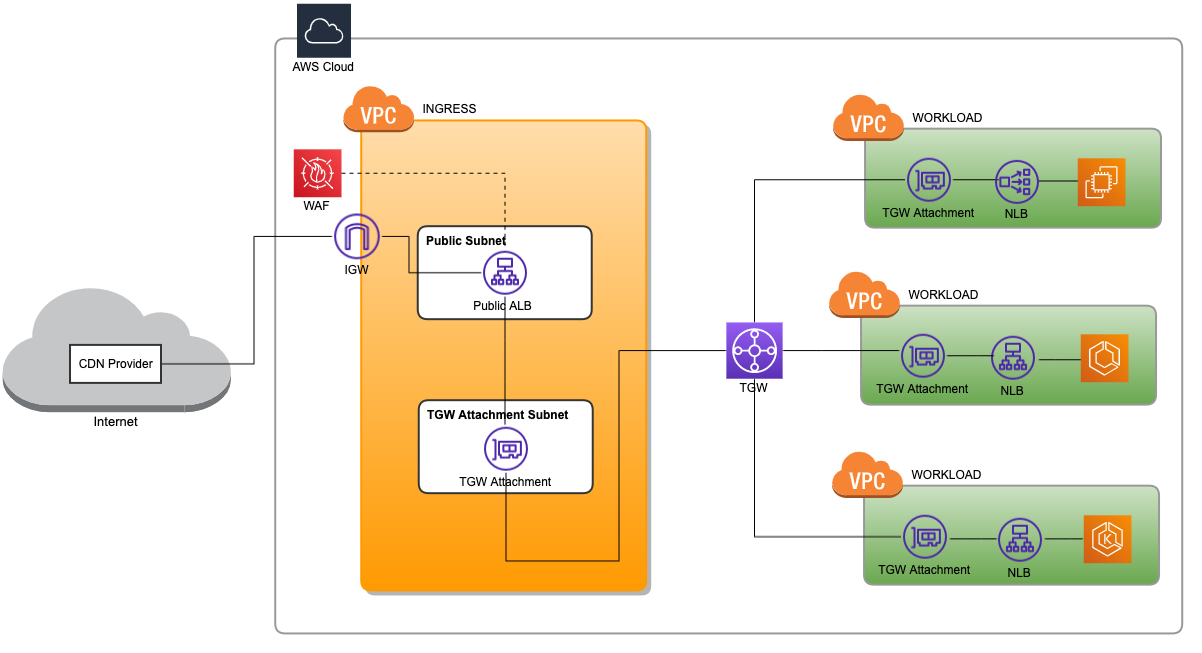
Below is the typical ingress solution for many organizations’ AWS workloads. The data flow is: Users -> CDN (e.g Akamai,Cloudflare) -> Ingress internet-facing ALB -> Ingress ASG (e.g Nginx, HAProxy) -> TGW -> Workload internal ALB -> Workload applications (ASG or K8S services).

As you can see, the improvements are the adoptions of some Cloud capabilities, e.g ALB (Elastic Application Load Balancer), ASG (Auto Scaling Group) and TGW (Transit Gateway). Essentially, it still follows the same pattern as what is normally done for on-premise ingress solution: Users -> CDN(e.g Akamai, Cloudflare) -> Public load balancer (e.g F5) -> Reverse proxy servers group (e.g Nginx, HAProxy) -> Internal load balancer (e.g F5) -> Application servers.
Are there anything you can think of to push the improvement to the next level? How about removing the Reverse Proxy ASG that is behind the Public ALB in the above diagram? The only thing it does is forwarding the traffics to the backend stacks, as the security parts are already looked after by both CDN WAF and AWS WAF.
We actually implemented it in our production environment more than half a year ago. So far so good! As illustrated below, this is our Serverless Ingress Solution. The two major changes comparing to the above diagram are:
- Removed the reserver proxy ASG (Auto Scaling Group) in the ingress VPC.
- Replaced the ALB (Application Load Balancer) with NLB (Network Load Balancer) in the workload VPC.
So now the forwarding function is performed directly by Ingress ALB -> Workload NLB, and the benefits are:
- Less hops quicker response time (no reverse proxy instances).
- Less maintenance overhead (patching or replacing reserver proxy instance etc).
- Lower cost (no EC2 costs).
- Not limited by the 50 target groups per autoscaling group any more.
Some gotcha that I learned along the way:
- NLB uses static IP addresses for its whole lifecycle. ALB uses NLB’s static IP addresses as its target group. So the workload team should not rebuild the NLB whenever they need to rebuild their application stack, or need to coordinate with the ingress solution team if they need to rebuild the NLB.
- Enable Host header preservation in the ingress ALB if the listeners are non-standard (80, 443) ports. Otherwise, the backend application will inherit the non-standard ports if there are any redirects.
- Enable cross-zone balancing in the workload NLB, as NLB DNS resolution only returns the IP address in the AZ which has healthy instances.
- Build a fallback mechanism in case the NLB is rebuilt without proper communication. Here is the example that I use in the schedule GitHub action.
Some food for thought, how about adding a firewall subnet in front of the public subnet? So we can use AWS Network Firewall to do more security inspections if required.
